Let’s talk about another application of least-squares in statistical learning applications. Say we have some data, and we want to separate them into groups. We have some data that we separate into training and validation sets that we know what groups they should be in. For data in an n-dimensional space (say, the data is defined by n coordinates, or in even simpler terms, has n features), we need to find hyperplanes of dimension n-1 that will SPLIT the space in half, where everything on one side is in one group, and everything on the other side of the hyperplane is in another (Intuitively, for our purposes, you can see 2D Euclidean space can be separated into two parts by a line, which is a 1 dimensional object, and a 3D euclidean space can be split by a plane, which is a 2D object).
So how do we find said hyperplane to divide up our space? The simplest way, and probably the most common way still just because it’s easy for a first-shot attempt at classification and linear regression, is to employ least-squares.
Let us say we have 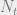

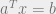
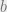

So let’s arrange the problem thusly; we want our 

So we have our rows of data points stacked on top of each other, with a column of 1s representing a constant offset of b in our hyperplane equation. The b vector is obviously then just going to be a stack of -1s and 1s for whatever class each row data point is matched to.
And then obviously since this is least squares, our resulting 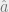
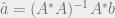
We have our hyperplane, now how do we do validation or classification of new data points? Recall that we classified our points using -1 and 1 teams. Adding a 1 to the tail of each data point like we did before to represent the constant b term in the hyperplane equation which we have in our coefficients, we can use our hyperplane equation’s left side, 
The MATLAB code below provides an example of a hyperplane separating two 2D Gaussian populations, and then trying to use that rule to classify data with a higher variance than we expected. A plot with training data points and the separating hyperplane is generated, and then a print out of percentage of correctly classified points is given at the end.
% generate 2 2D pops ndim = 2; pop_size = 20; u1 = [4, 4]; u2 = [-2, -1]; covar_mat = 5.*eye(2); pop1 = bsxfun( @plus, randn(pop_size, ndim)*chol(covar_mat), u1 ); pop2 = bsxfun( @plus, randn(pop_size, ndim)*chol(covar_mat), u2 ); figure; plot( pop1(:,1), pop1(:,2), '*b' ); hold on; plot( pop2(:,1), pop2(:,2), 'xr' ); % find the hyperplane that goes through the middle using least squares A = [[pop1; pop2], ones(2*pop_size,1)]; b = [-1.*ones( pop_size, 1 ); 1.*ones(pop_size,1)]; coefs = lscov(A, b); % plot the coefficient line using that learning data we generated line_x = [-20; 20]; line_y = (-coefs(end)-coefs(1).*line_x)./coefs(2); plot( line_x, line_y, '-k' ); xlim( [-20, 20] ); ylim( [-20, 20] ); % now let's try to classify the new points we generate covar_mat2 = 8.*eye(2); new_pop1 = bsxfun( @plus, randn(pop_size, ndim)*chol(covar_mat2), u1 ); new_pop2 = bsxfun( @plus, randn(pop_size, ndim)*chol(covar_mat2), u2 ); combined_newpop = [new_pop1; new_pop2]; new_inds = randperm( (2*pop_size) ); actual_population = b(new_inds); combined_newpop = combined_newpop( new_inds, : ); newpop_w_ones = [combined_newpop, ones(2*pop_size, 1)]; classify = sum( bsxfun( @times, newpop_w_ones, coefs(:)' ), 2); classify(classify < 0) = -1; classify(classify >= 0) = 1; percent_correct = sum(classify == actual_population)./(2*pop_size)
So what’s wrong with this? The clearest problem is that this method really implies that groups are linearly separable, and a lot of times, it’s not that simple. This method also tends to allow outliers to have really heavy effects on the resulting lines, and generally does poorly for classification of more than 2 groups, no matter how you decide to handle the multiple group problem (1v1 hyperplanes or 1 vs everybody else hyperplanes, either way). Inherently, since linear least squares is optimal ML estimator for Gaussian populations, you are inherently assuming multivariable Gaussian distributed stuff, and even if it is, there’s somewhat of a disregard for prior information, say, covariance matrices or anything else that might help.
Since the follow up is natural and I really want to get this stuff nailed down for myself, next time we will talk about linear discriminant analysis, and then after that, quadratic discriminant analysis. I personally think of LDA and QDA as a more thorough treatment of the linear classification problem by stating assumption and taking in account parameters that may help us, plus QDA has the benefit of generating quadratic lines.

This was extremely useful, thank you, I had been struggling with concept for ages.