Break from statistics. I want to talk about digital signal processing again. So I talked about FIR filters before, let’s talk about IIR filters. Like how to recognize them, analysis, maybe things like direct form type I and II later, and then at least simpler design like Butterworth IIR filter design, and a mention of the transforms to go from analog to digital domain.
So what is an infinite impulse response filter? Well, it’s a filter such that a resulting signal from passing something through doesn’t really ever die off completely. Lemme bring back the easy example I used in my FIR filter post.
![y[n] - .5y[n-1] = x[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D+-+.5y%5Bn-1%5D+%3D+x%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Let’s say our input is a Kronecker delta such that ![x[0] = 1](https://s0.wp.com/latex.php?latex=x%5B0%5D+%3D+1&bg=eeeeee&fg=666666&s=0&c=20201002)
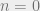
![y[n] = 1](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+1&bg=eeeeee&fg=666666&s=0&c=20201002)
![y[n] = x[n] + .5y[n-1] = 0 + .5 = .5](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+x%5Bn%5D+%2B+.5y%5Bn-1%5D+%3D+0+%2B+.5+%3D+.5&bg=eeeeee&fg=666666&s=0&c=20201002)
![y[n] = x[n] + .5y[n-1] = 0 + .25 = .25](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+x%5Bn%5D+%2B+.5y%5Bn-1%5D+%3D+0+%2B+.25+%3D+.25&bg=eeeeee&fg=666666&s=0&c=20201002)
So how can we find the impulse response? We can use the z-transform like we did for FIR filters.

We know our impulse response is output over input, so
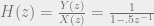
And of course, if the region of convergence for our z-transform includes the unit circle, we can find the discrete-time Fourier transform simply by replacing z with 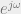
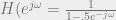
And just like that, we have our impulse response for our IIR filter. Yeah, this one is kind of trivial but it’s just for teaching purposes.
So how do we know if our IIR filter is stable? With FIR filters, we knew it was going to be stable no matter what. The output signal would end, assuming input was bounded and finite already. If we look at our IIR filter Z-transform, given a more complex one, we can see that with a polynomial on top and bottom, we will have zeros such that some complex values of z will make the filter equal to 0, and we will have some poles such that some values of z make the filter shoot to infinity. The general rule is that given a CAUSAL filter, like one that doesn’t somehow go backward in time, if the poles are inside of the unit circle, the unit circle is included in the region of convergence and our filter is stable. So that’s cool. I mean, if zeros are inside of the unit circle, then we also have less of a phase mess-up problem too, but that’s less of a problem than unstable filters.
So what are the pros and cons of IIR filters? In a lot of situations, IIR filters can get the desired filter response wanted using significantly fewer filter coefficients than FIR filters. In many situations, IIR filters that have been turned into biquads or filter banks, basically split into packs of smaller IIR filters, are pretty computationally efficient if you don’t have the luxury of doing zero-padded FFTs for FIR filters.
The downsides? IIR filters tend to be pretty sensitive to limitations of computer numbers. If the machine precision isn’t good enough, the actual filter behavior may not function as planned. Even if the filter acts like you’d expect at the beginning, the numerical precision thing leads into a feedback problem, say the filter behavior EVENTUALLY turns into garbage because of numerical limitations. This can be solved with a zeroing of values, basically resetting the filter, at some point, but that may mean tossing out information. Additionally, IIR filters aren’t conveniently linear phase or zero-phase like FIR counterparts can be designed, so if you need real-time signal processing, get ready to have some phase changes. These can be minimized if the filter is designed such that zeros are within the unit circle. Additionally, if the real-time requirement isn’t there, you can do a forward-backward filter process to have a zero-phase filter by simply doing the filter, and then using a time-reversed version of the filter.
I’m too lazy to fire up python or matlab, but you can use the examples from the FIR filter to do analysis of IIR filters. freqz(b,a,n) in both python and matlab are designed such that b is a vector of coefficients in the numerator of H(z), a is a vector of coefficients in the denominator of H(z), and n is some number of samples that basically lets you set a resolution to look at. Note that for FIR filters, we set a = 1 because we don’t have any denominator to H(z) to worry about.
 and SYMMETRIC densities of
and SYMMETRIC densities of 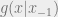 (symmetric meaning
(symmetric meaning  ) that we are drawing samples from, where g is conditioned on the previous sample we had accepted,
) that we are drawing samples from, where g is conditioned on the previous sample we had accepted,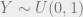 , which we’ll MIGHT be using to make our decision whether or not to keep or reject the new sample.
, which we’ll MIGHT be using to make our decision whether or not to keep or reject the new sample. , such that the PDF of the new sample is larger than the previous one, we keep our new sample straight up. Otherwise, we need to do a check against our uniformly distributed value; if our uniformly distributed random sample
, such that the PDF of the new sample is larger than the previous one, we keep our new sample straight up. Otherwise, we need to do a check against our uniformly distributed value; if our uniformly distributed random sample 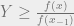 , then we keep the new sample x. Otherwise, we reject x.
, then we keep the new sample x. Otherwise, we reject x.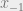 is replaced with the x we just got. Go back to step 1 and keep doing it until we have enough values.
is replaced with the x we just got. Go back to step 1 and keep doing it until we have enough values. 
 samples of basically any probability density. The idea behind it is that we can sample a random variable by sampling uniformly underneath the graph of a density function.
samples of basically any probability density. The idea behind it is that we can sample a random variable by sampling uniformly underneath the graph of a density function.  that we are drawing samples from,
that we are drawing samples from,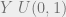 , which we’ll be using to make our decision whether or not to keep or reject the new sample.
, which we’ll be using to make our decision whether or not to keep or reject the new sample.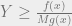 , then we keep x. Otherwise, we reject x.
, then we keep x. Otherwise, we reject x.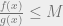 so that step 2 actually makes sense, avoiding violating axioms of probability.
so that step 2 actually makes sense, avoiding violating axioms of probability. 