I feel like I need to publish something quick, so I’ll just discuss stationary distributions for Markov Chains real quick before my orientation stuff at Cisco in California. I don’t necessarily know if I have time to make a post while I’m there.
We’ve discussed Markov Chains previously. Given a set of states, say n states such that 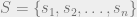
where the transition matrix entry 

For simplicity, you can assume our Markov Chain is time-invariant, meaning the probabilities in the transition matrix don’t change over time. I believe what we are discussing here will hold, but definitely not in a obvious and conveniently calculable way, like there’s going to be symbols and stuff, and potentially you’d probably have to prove that the markov chain remains positive recurrent over time, weird shit, let’s not get into that. Let’s assume we have a nice matrix full of constants that don’t change with each time step.
So say we have a starting distribution of what state we might be in, a row vector x such that ![X_{0} = [x_{1}, x_{2}, \hdots, x_{n}]](https://s0.wp.com/latex.php?latex=X_%7B0%7D+%3D+%5Bx_%7B1%7D%2C+x_%7B2%7D%2C+%5Chdots%2C+x_%7Bn%7D%5D&bg=eeeeee&fg=666666&s=0&c=20201002)

So a stationary distribution is when we have some row vector Y such that 

But linear algebra people should recognize that Y here is actually a LEFT eigenvector! You can solve for this simply by solving for the (right) eigenvectors of 
Obviously, there has to be a catch to this bit, right? So there are three things that could happen with stationary Markov chains.
1. unique stationary distribution
2. multiple unique final distributions
3. oscillating/alternative final distributions
The uniqueness of the stationary distribution is only guaranteed iff the MC is positive-recurrent. What does that even mean? The simplest way to find it is by making sure each state is reachable at any time, i.e. they are all recurring states, and that the periodicity of each state going back to itself eventually has a greatest common factor of 1 (like there could be a state that goes back to itself potentially even 2 steps at the quickest, but somebody else could only do it in minimum 3 steps, then the GCF is 1). In linear algebra terms, this effectively guarantees the matrix is full rank, geometric multiplicity of eigenvalue 1 is 1 (there’s only 1 eigenvector associated with eigenvalue 1), and there’s no weird thing involving eigenvector -1.
How do 2 and 3 even occur then? 2, if you effectively have transient states, or just completely separable Markov chains you happened to put into the same matrix (like with 5 states, if states 1-3 communicated amongst themselves and 4,5 communicated only between themselves), you will end up with more than 1 stationary distribution at the end. In case 3, if there’s some periodicity going on, then clearly it’s possible that the Markov chain will have some alternating with each time step and not actually be stationary by the end, though it will have converged to a set of probability vectors. Generally, you may end up with a eigenvector for eigenvalue 1, and then an eigenvector for eigenvalue -1 that will represent the change in the distribution with every time step.
 training data points of n dimensions, training points each designated at
training data points of n dimensions, training points each designated at  , for the ith index training point, jth coordinate . These training points belong to two classes, which we’ll classify as the -1 team and the 1 team. Since hyperplanes are represented most easily in equation
, for the ith index training point, jth coordinate . These training points belong to two classes, which we’ll classify as the -1 team and the 1 team. Since hyperplanes are represented most easily in equation 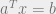 , where where
, where where 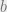 is a constant and
is a constant and  is an n-dimensional vector of coefficients, our goal here is to solve for the a coefficients and the b constant.
is an n-dimensional vector of coefficients, our goal here is to solve for the a coefficients and the b constant. matrix for the least squares problem to contain our data points, such that
matrix for the least squares problem to contain our data points, such that
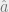 vector of coordinates is going to be
vector of coordinates is going to be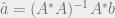
 , and simply classify points depending if the result is negative or positive!
, and simply classify points depending if the result is negative or positive!![y[n] = \sum_{l=0}^{L} h[l] x[n-l] + v[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+%5Csum_%7Bl%3D0%7D%5E%7BL%7D+h%5Bl%5D+x%5Bn-l%5D+%2B+v%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002) , where h is our discretized channel, x is the sent signal, and v is additive white Gaussian noise.
, where h is our discretized channel, x is the sent signal, and v is additive white Gaussian noise.
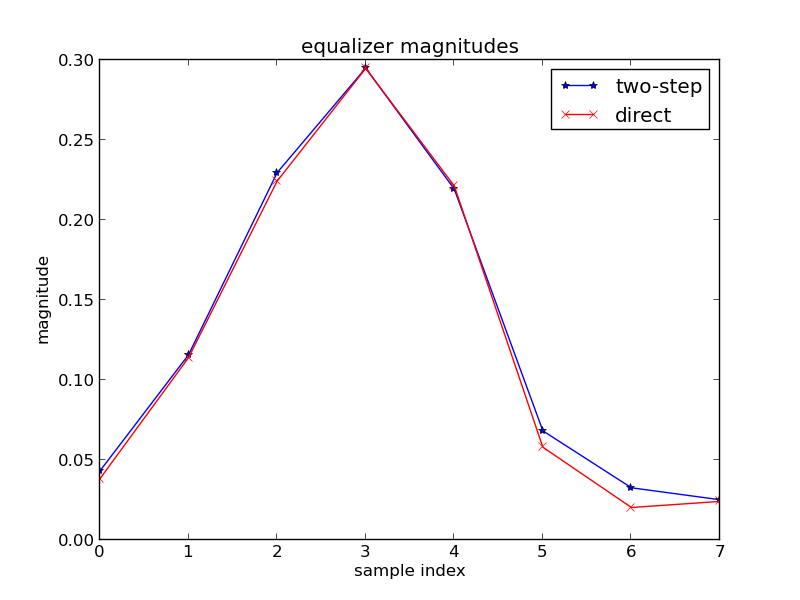
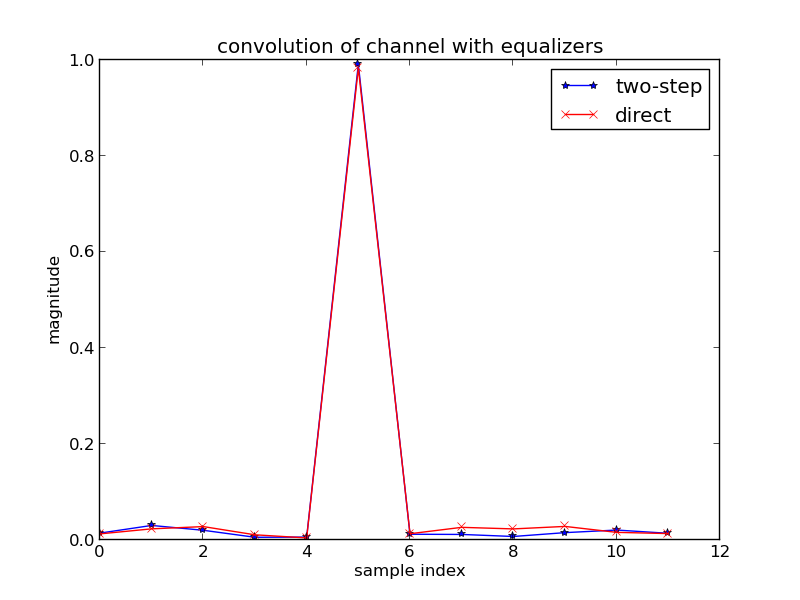

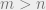 , or A is a tall matrix. We call A an overdetermined matrix. Simply put, there are way too many unique linear equations to solve for a unique x vector answer. So what do we do? We can use least-squares formulation of the problem to get some sort of an acceptable answer. If we multiply by sides of the equation by the Hermitian transpose of A, we get
, or A is a tall matrix. We call A an overdetermined matrix. Simply put, there are way too many unique linear equations to solve for a unique x vector answer. So what do we do? We can use least-squares formulation of the problem to get some sort of an acceptable answer. If we multiply by sides of the equation by the Hermitian transpose of A, we get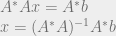

 , or A is a fat matrix, A is then an underdetermined matrix, and we have a large solution space. The vector x could be a whole number of things! What’s neat about least squares is that we can still use it here for a similar purpose.
, or A is a fat matrix, A is then an underdetermined matrix, and we have a large solution space. The vector x could be a whole number of things! What’s neat about least squares is that we can still use it here for a similar purpose.
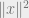 is minimized. There are places in optimization or control theory where we want the minimum energy vectors for controllability or stability, so the underdetermined least-squares problem is useful as well.
is minimized. There are places in optimization or control theory where we want the minimum energy vectors for controllability or stability, so the underdetermined least-squares problem is useful as well.