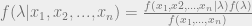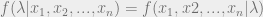Previously, we discussed the maximum a posteriori estimator and the maximum likelihood estimator. We gathered that using given data, we can make use of Bayes’ theorem and make a solid guess at parameters of a probability distribution, given the data we got and any prior knowledge. Even if we had no prior distribution, we could just get a solid guess thanks to MLE.
But let’s say the situation got a little more complicated. Last time, we discussed classification by linear discriminant analysis (LDA) and quadratic discriminant analysis (QDA), but those technically require us to have the parameters for the distributions of each class known ahead of time. So what if we need to guess that? Each class is going to have a distribution, and we have a bunch of data with no known classes, so how can we bridge the gap and not only classify our data but make a guess at the parameters of each class?
So the Expectation-Maximization algorithm gives us a method to basically try our best to get all the things we want to solve for above, landing at a possible local solution but maybe not the actual answer. Which is fine, we’re just making a guess. Sometimes that’s the best we can do.
Informally, what the algorithm entails is looping the E and M steps until convergence.
1. Expectation step: Using the prior from the previous step, find the expected value of the underlying variables we need in our setup; e.g. for classification, let’s classify the points by choosing the class we would expect each data point to be in, given our prior distributions from the previous step.
2. Maximization step: using the underlying variables we just solved for in the E step, use maximum likelihood estimators to find parameters for the distributions of whatever we’re looking for, e.g. for classification, the distribution of the classes.
In more formal math terms, lets say X is a vector of data, Z is the underlying variables we need, 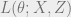
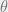
1. Expectation step; calculate the expected value
2. Maximization step; calculate new
![F(\theta | \theta^{(n)}) = E_{Z | X, \theta^{(n)}}[L(\theta | X,Z)]](https://s0.wp.com/latex.php?latex=F%28%5Ctheta+%7C+%5Ctheta%5E%7B%28n%29%7D%29+%3D+E_%7BZ+%7C+X%2C+%5Ctheta%5E%7B%28n%29%7D%7D%5BL%28%5Ctheta+%7C+X%2CZ%29%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
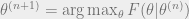
So how would we do this for our little Gaussian mixture model we wanted to classify in the previous post? We have m classes, n data points (for now, let’s assume n >> m, we have tons of data). Making guesses at our parameters initially for each class, we do EM by repeating the following 2 steps.
1. Expectation step: find which class a point belongs to using LDA or QDA classifiers from the previous post (the assumptions each one assumes applied here, so choose one and stick with it).
2. Maximization step: for each class, use the points associated with it to find the sample mean. For LDA, we find the sample covariance matrix using all points so this won’t change between iterations, but for QDA, we need to also find the sample covariance matrix for each class.
If we wanted to entire ignore covariance in this calculation, you could actually see that k-means using a simple distance measure to decide on classes for the expectation step is basically an expectation maximization algorithm! Additionally, you can see that Baum-Welch is a variant of this for Hidden Markov Models where during our expectation step, we guess what states our system is in, and then use that to make a guess at our observation and state transition matrices.
Couple things: clearly, EM is a very general idea; the algorithm details need to be changed depending on the problem, i.e. things aren’t just Gaussian all the time, we need to adjust EM to suit our problems. EM algorithm tends to fall into a local solution but not necessarily the solution you want, and of course this changes when different priors and starting points are involved in the problem formulation. In the case of Baum-Welch and some other cases, EM algorithm isn’t even guaranteed to converge. So the EM algorithm needs to be used with care, though it is extremely powerful and has been proved to have some level of correctness.
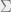 is a covariance matrix, and
is a covariance matrix, and  is a vector mean) is given as
is a vector mean) is given as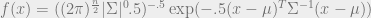
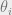 is the probability of data point being from class i, then it also follows
is the probability of data point being from class i, then it also follows  just by simple axioms of probability.
just by simple axioms of probability.
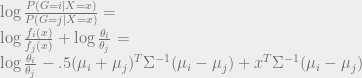
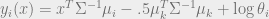

![x = [x_{1}, x_{2}, x_{3}]^{T}](https://s0.wp.com/latex.php?latex=x+%3D+%5Bx_%7B1%7D%2C+x_%7B2%7D%2C+x_%7B3%7D%5D%5E%7BT%7D&bg=eeeeee&fg=666666&s=0&c=20201002) , then we could have a modified
, then we could have a modified  such that
such that ![\bar{x} = [x_{1}, x_{2}, x_{3}, x_{1}x_{2}, x_{2}x_{3}]^{T}](https://s0.wp.com/latex.php?latex=%5Cbar%7Bx%7D+%3D+%5Bx_%7B1%7D%2C+x_%7B2%7D%2C+x_%7B3%7D%2C+x_%7B1%7Dx_%7B2%7D%2C+x_%7B2%7Dx_%7B3%7D%5D%5E%7BT%7D&bg=eeeeee&fg=666666&s=0&c=20201002) . And generally, this higher dimensional trick used in support vector machines tends to net LDA results that are pretty similar to QDA results, so QDA is the preferred way to go with LDA being used if needed. I mean, at this point in time, it always makes sense to spend more computation time to use more existing prior data.
. And generally, this higher dimensional trick used in support vector machines tends to net LDA results that are pretty similar to QDA results, so QDA is the preferred way to go with LDA being used if needed. I mean, at this point in time, it always makes sense to spend more computation time to use more existing prior data.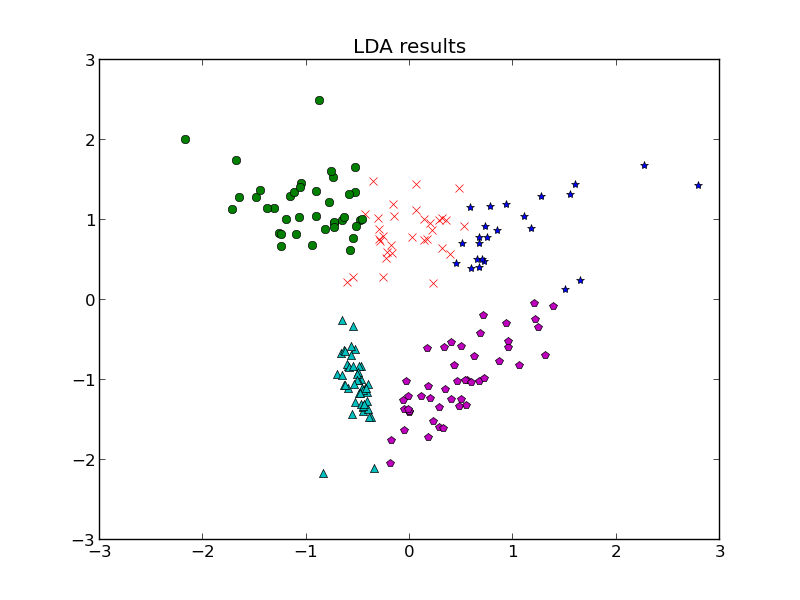


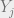 for each time step 1 to k. A and O can be filled with appropriate uniform probability values if we really have no idea what should go in there.
for each time step 1 to k. A and O can be filled with appropriate uniform probability values if we really have no idea what should go in there.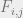 and backward probabilities
and backward probabilities  , where the subscripts mean state i, time step j, where F and B are both 2D arrays with n rows and k+1 columns.
, where the subscripts mean state i, time step j, where F and B are both 2D arrays with n rows and k+1 columns. is the probability of being at state i at time j.
is the probability of being at state i at time j. at time j, and
at time j, and 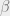 at time j+1, which we can find using the following calculation.
at time j+1, which we can find using the following calculation.
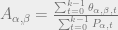
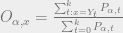 . This is calculating the probabilities of being in a state at the times that the observation x happened divided by the probabilities that we are in that state at any time.
. This is calculating the probabilities of being in a state at the times that the observation x happened divided by the probabilities that we are in that state at any time. , and if we need it, we can have them all in a vector,
, and if we need it, we can have them all in a vector, 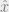 . We guess that for sample is independent, and distributed exponentially, i.e. each sample is drawn from a probability distribution with the PDF of
. We guess that for sample is independent, and distributed exponentially, i.e. each sample is drawn from a probability distribution with the PDF of
 actually is. Well, what can we do? We know from Bayes theorem,
actually is. Well, what can we do? We know from Bayes theorem,