This was something I remembered from EE 381V Wireless Communications Lab at UT Austin, taught by Dr. Robert Heath. It’s a nice practical way of showing how useful least-squares is, even for something that doesn’t really suggest its use at first glance.
So let’s say we have a wireless node communicating with another wireless node, using this simple baseband model.

where x is what we transmitted, v is a AWGN process, h is the channel in effect with a delay spread of T, and y is the received signal. We sample it, assuming our RF stuff modulates it down nicely, and we satisfy Nyquist so we don’t have aliasing issues,
![y[n] = \sum_{l=0}^{L} h[l] x[n-l] + v[n]](https://s0.wp.com/latex.php?latex=y%5Bn%5D+%3D+%5Csum_%7Bl%3D0%7D%5E%7BL%7D+h%5Bl%5D+x%5Bn-l%5D+%2B+v%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
So n is our sample index, and m is our discrete convolution dummy variable, L is how long the channel delay spread is in samples (or so we think). So to get our message back at the receiver, assuming noise is small for now, we need to estimate the channel affecting our communications at this very moment. And how do we do that?
If we sent a known training sequence in our transmission, then we can use that to estimate the channel of our system. We can set up a linear system as follows, under the assumption that x is the training sequence t, with 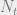
![\begin{bmatrix} y[L] \\ y[L+1] \\ \vdots \\ y[N_{t}-1] \end{bmatrix} = \begin{bmatrix} t[L] & \hdots & t[0] \\ t[L+1] & \ddots & \vdots \\ \vdots & & \vdots \\ t[N_{t}-1] & \hdots & t[N_{t}-1-L] \end{bmatrix} \begin{bmatrix} a[0] \\ a[1] \\ \vdots \\ a[L] \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Bbmatrix%7D+y%5BL%5D+%5C%5C+y%5BL%2B1%5D+%5C%5C+%5Cvdots+%5C%5C+y%5BN_%7Bt%7D-1%5D+%5Cend%7Bbmatrix%7D+%3D+%5Cbegin%7Bbmatrix%7D+t%5BL%5D+%26+%5Chdots+%26+t%5B0%5D+%5C%5C+t%5BL%2B1%5D+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cvdots+%26+%26+%5Cvdots+%5C%5C+t%5BN_%7Bt%7D-1%5D+%26+%5Chdots+%26+t%5BN_%7Bt%7D-1-L%5D+%5Cend%7Bbmatrix%7D+%5Cbegin%7Bbmatrix%7D+a%5B0%5D+%5C%5C+a%5B1%5D+%5C%5C+%5Cvdots+%5C%5C+a%5BL%5D+%5Cend%7Bbmatrix%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
We can see that we imitated the discrete convolution operator using this Toeplitz matrix. Intuitively, you can see we turned the training around in time, and then lined it up so that it shifts one sample at a time while multiplying and summing, so it is definitely a convolution expressed in linear algebra. Of course, assuming we have enough training samples such that the A matrix is tall, we can solve for h[n] using Least squares.
NOTE: do NOT do channel estimation with a fat matrix. If you recall from another post, we get a solution with a minimum power, and that really doesn’t help us at all here since it’s like saying our channel has several different possible solutions with an overdetermined linear system.
What can we do with this channel? We can solve for a filter that will allow us to cancel out the effects of this channel on our communications, and then use that filter on the rest of our payload. Our goal is to find an equalizer ![f[n]](https://s0.wp.com/latex.php?latex=f%5Bn%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
$latex \sum_{l=0}^{L_{f}} h[l] f[n-l] = \delta[n]$
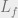
![\sum_{l=0}^{L_{f}} h[l] f[n-l] = \delta[n-k]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bl%3D0%7D%5E%7BL_%7Bf%7D%7D+h%5Bl%5D+f%5Bn-l%5D+%3D+%5Cdelta%5Bn-k%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
Using this idea, we can set up a similar problem as before, using the Toeplitz matrix for our convolution again.
![\begin{bmatrix} h[0] & 0 & \hdots & \hdots \\ h[1] & h[0] & 0 & \hdots \\ \vdots & \ddots & & \\ h[L] & & & \\ 0 & h[L] & \hdots & \\ \vdots & & & \end{bmatrix} \begin{bmatrix} f[0] \\ f[1] \\ \vdots \\ \vdots \\ \vdots \\ f[L_{f}] \end{bmatrix} = \begin{bmatrix} 0 \\ \vdots \\ 1 \\ \vdots \\ \vdots \\ 0 \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Bbmatrix%7D+h%5B0%5D+%26+0+%26+%5Chdots+%26+%5Chdots+%5C%5C+h%5B1%5D+%26+h%5B0%5D+%26+0+%26+%5Chdots+%5C%5C+%5Cvdots+%26+%5Cddots+%26+%26+%5C%5C+h%5BL%5D+%26+%26+%26+%5C%5C+0+%26+h%5BL%5D+%26+%5Chdots+%26+%5C%5C+%5Cvdots+%26+%26+%26+%5Cend%7Bbmatrix%7D+%5Cbegin%7Bbmatrix%7D+f%5B0%5D+%5C%5C+f%5B1%5D+%5C%5C+%5Cvdots+%5C%5C+%5Cvdots+%5C%5C+%5Cvdots+%5C%5C+f%5BL_%7Bf%7D%5D+%5Cend%7Bbmatrix%7D+%3D+%5Cbegin%7Bbmatrix%7D+0+%5C%5C+%5Cvdots+%5C%5C+1+%5C%5C+%5Cvdots+%5C%5C+%5Cvdots+%5C%5C+0+%5Cend%7Bbmatrix%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
Now, we get a filter we can use in our communication system to recover our original signal using least squares again. But two least-squares calculations is kind of a lot of work, why do two when we can do one?
If we change our formulation such that we want to recover the original training sequence with our received channel-affected training sequence, we can formulate the following problem,
![\sum_{l=0}^{L_{f}} f[l] y[n-l] = t[n-k]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bl%3D0%7D%5E%7BL_%7Bf%7D%7D+f%5Bl%5D+y%5Bn-l%5D+%3D+t%5Bn-k%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
And just like that, we can solve for our filter in a direct step using the following linear system
![\begin{bmatrix} t[0] \\ t[1] \\ \vdots \\ t[N_{t}-1] \end{bmatrix} = \begin{bmatrix} y[k] & \hdots & y[k-L_{f}] \\ y[k+1] & \ddots & \vdots \\ \vdots & & \vdots \\ y[k+N_{t}-1] & \hdots & y[k+N_{t}-L_{f}] \end{bmatrix} \begin{bmatrix} f[0] \\ f[1] \\ \vdots \\ f[L_{f}] \end{bmatrix}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Bbmatrix%7D+t%5B0%5D+%5C%5C+t%5B1%5D+%5C%5C+%5Cvdots+%5C%5C+t%5BN_%7Bt%7D-1%5D+%5Cend%7Bbmatrix%7D+%3D+%5Cbegin%7Bbmatrix%7D+y%5Bk%5D+%26+%5Chdots+%26+y%5Bk-L_%7Bf%7D%5D+%5C%5C+y%5Bk%2B1%5D+%26+%5Cddots+%26+%5Cvdots+%5C%5C+%5Cvdots+%26+%26+%5Cvdots+%5C%5C+y%5Bk%2BN_%7Bt%7D-1%5D+%26+%5Chdots+%26+y%5Bk%2BN_%7Bt%7D-L_%7Bf%7D%5D+%5Cend%7Bbmatrix%7D+%5Cbegin%7Bbmatrix%7D+f%5B0%5D+%5C%5C+f%5B1%5D+%5C%5C+%5Cvdots+%5C%5C+f%5BL_%7Bf%7D%5D+%5Cend%7Bbmatrix%7D&bg=eeeeee&fg=666666&s=0&c=20201002)
So how do we choose equalizer length, and number of samples to delay time? Rule for the equalizer in general is longer equalizers gives more accurate results in exchange for longer computation, but at the very least, shoot for being equivalent in length to the actual channel. The number of samples to delay time when solving for the equalizer, you usually need to solve for several equalizers using different delay values and choose the best one, but a rule of thumb from Dr. John Cioffi’s textbook is that you the floor of the average of channel length and equalizer length, i.e., 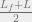
Additionally, we ignored noise this entire time. What should we do if we have strong noise? Saving it for another post, but we can have a minimum mean square error equalizer if we know the noise power and covariance ahead of time.
So later post, minimum mean square error filter, and programming implementation of the filter in Python and/or MATLAB.
